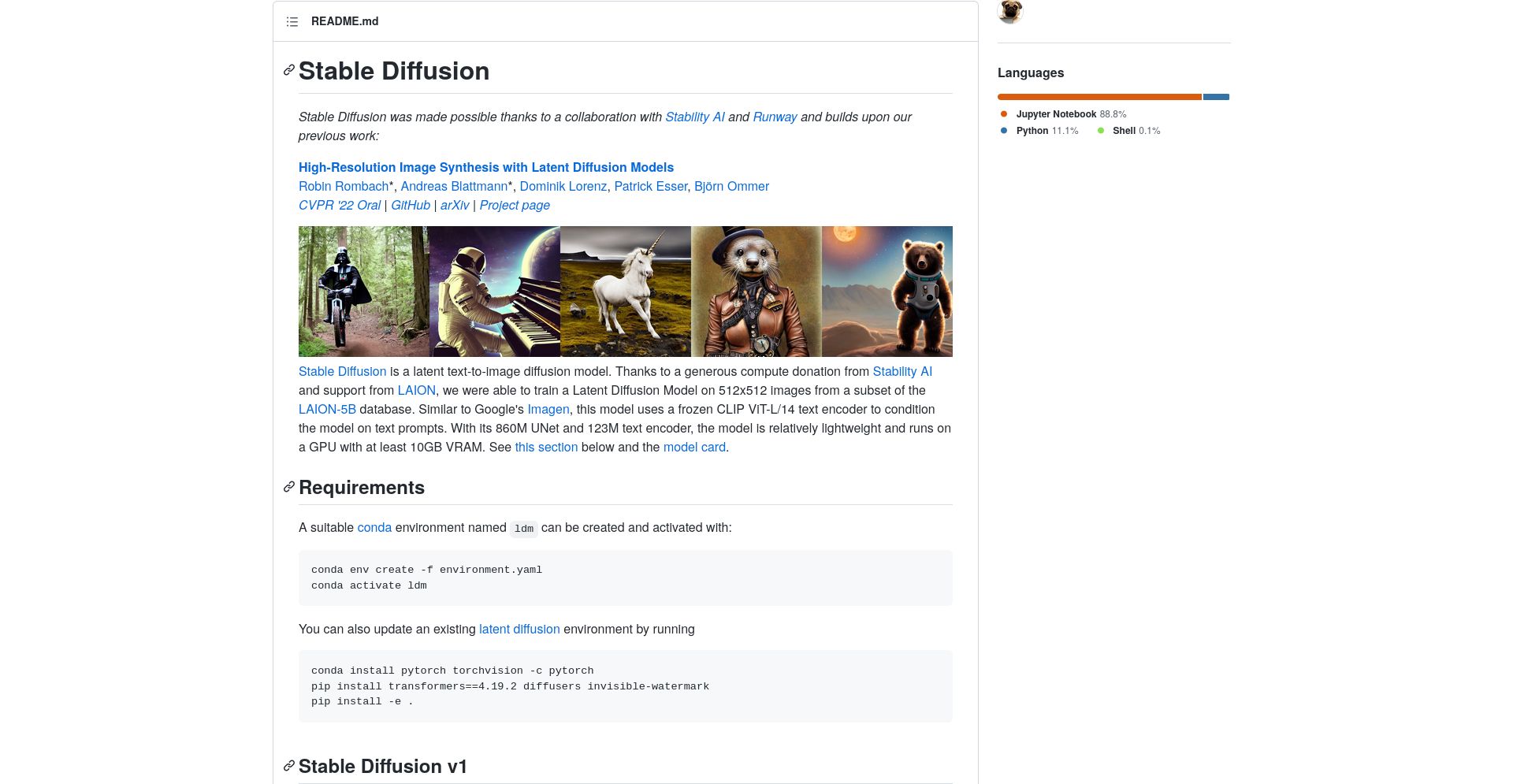
CompVis/stable-diffusion is a latent text-to-image diffusion model which allows users to create images using text and GPT. It provides access to a library of pre-trained models, so users can quickly get started with the software.
The main benefits of using CompVis/stable-diffusion are: access to a library of pre-trained models; use of GPT for text generation; and creation of images from text.
Possible use cases for CompVis/stable-diffusion include creating visuals from storytelling, visualizing data from surveys and reports, or generating illustrations for scientific papers
Screenshots