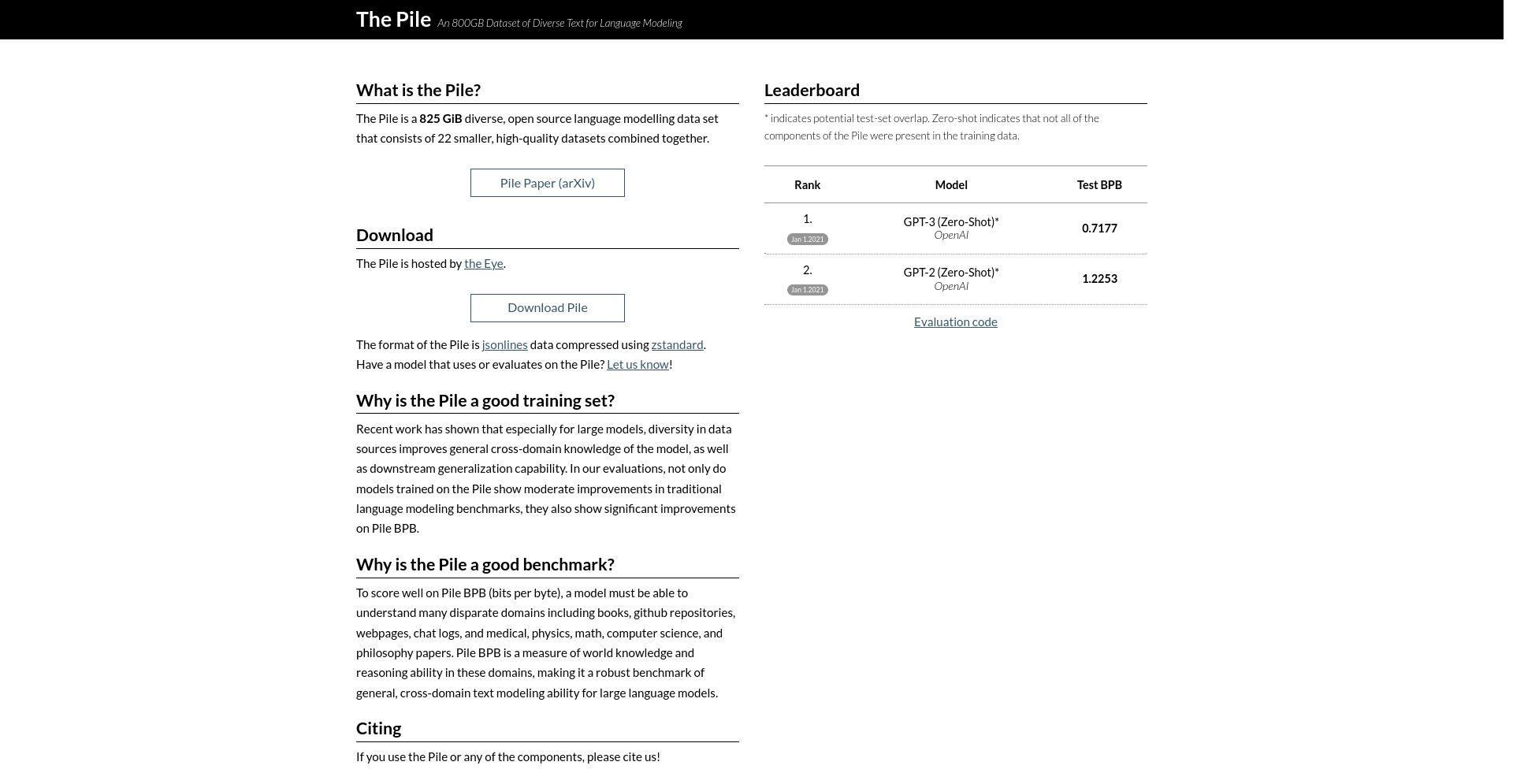
The Pile is an 825 GiB open source language modelling data set that consists of 22 smaller, high-quality datasets. It is hosted by the Eye and can be downloaded in jsonlines format compressed using zstandard.
Benefits to the user include:
- Diversity in data sources improves general cross-domain knowledge of the model
- Moderate improvements in traditional language modeling benchmarks
- Significant improvements on Pile BPB (bits per byte)
Possible use cases for The Pile include leveraging the power of GPT text generation for natural language processing fields such as machine translation, text summarization, and question answering.
Screenshots